
Your autopilot is only as good as your plan
Vibe coding in the terminal is a different beast from an IDE. There is no sidebar, no inline ghost text, no visual scaffolding. Just you, a prompt, and whatever Copilot decides to do with it. That constraint forces you to be deliberate about when you reach for the model and what you ask it to do.
The biggest lever I found for cutting wasted iterations was not prompt engineering. It was understanding how the three CLI modes work, what each one is actually for, and when to trust Auto model selection versus when to pin something specific.
A note on how Auto model selection works
Before getting into the phases, it helps to understand what happens when you leave model selection on Auto. It is not random and it is not just picking the most capable model available.
Auto follows a priority stack. First it applies your organisation’s policy filter, so if your company has blocked certain models, they are out of the pool entirely regardless of what you ask for. Then it avoids unnecessarily expensive models by default, reaching for a faster, cheaper model when that is sufficient, and escalating when the task complexity warrants it. The practical effect is that Auto is conservative by default.
This matters because manually pinning a heavy reasoning model for every prompt is not actually the right move. It burns premium requests on work that does not need them. The right approach is to understand when Auto will make a good choice on its own, and when you need to override it.
Read this article for more information, and this article for Auto Models.
The Three Modes
Plan
copilot --mode plan is a staging area.
You discuss the approach, Copilot lays out what it intends to do, and nothing touches your files until you say so. Most people skip this and go straight to Autopilot with a half-formed goal. That is where the iteration debt starts.
For planning work, I pin a strong reasoning model manually.
Auto will often route plan-mode prompts to something cost-efficient, which is fine for a simple script but not for feature-level architectural thinking. A stronger reasoning model will push back on assumptions you did not know you were making. That pushback is the whole point of Plan mode. The extra latency is worth it.
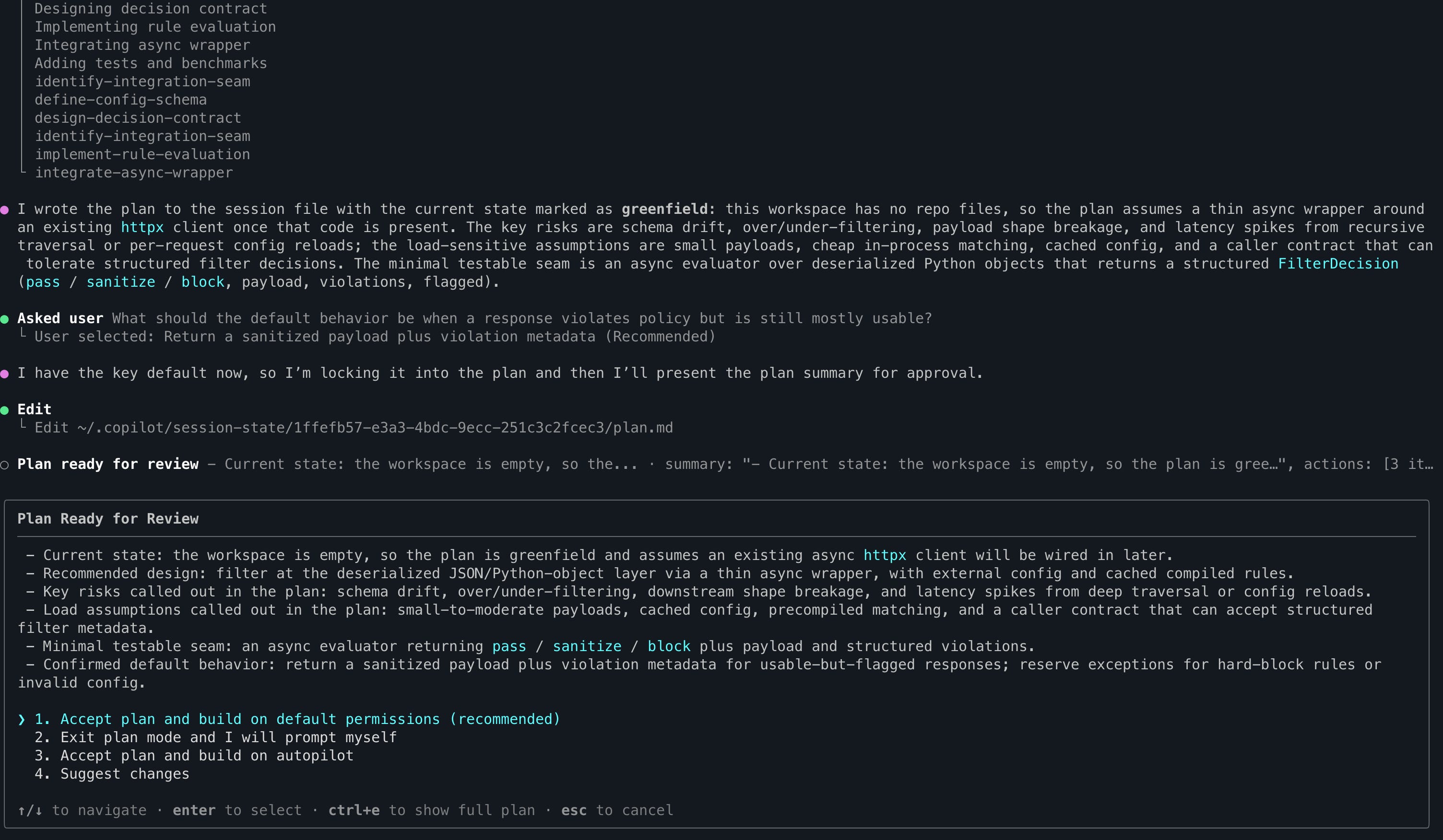
Getting to a plan you trust usually takes a few rounds, not one shot.
My first attempt at the prompt below asked for failure modes and got a decent list. But the plan was still too vague to hand to Autopilot safely. It described what to build without specifying the contract, the boundaries, or the test scenarios. I had to go back and explicitly ask for spec-driven development: user stories with acceptance criteria, a traceable todo list, a defined core contract, and unit test scenarios written from the stories. That conversation took a few rounds.
The plan that came out of it was something I could actually use.
Here is what the initial prompt looked like, built up across those iterations, for a content filtering agent that intercepts third-party API responses in Python 3.11:
copilot --mode plan --model <your strongest reasoning model>
I need to build a Python agent that filters API responses from a third-party
data provider before they reach our application layer. Here is the context:
Goal:
Intercept API responses and strip or flag content that violates our policy
(PII, profanity, off-topic categories). Pass clean responses through unchanged.
Stack:
- Python 3.11
- No new packages beyond what is already in requirements.txt
Constraints:
- Must be a thin middleware layer, not a rewrite of the existing API client
- Latency budget is 50ms added overhead max
- Filtering rules will change frequently; config must be external, not hardcoded
- Async; the existing client uses httpx with async/await throughout
What I am NOT sure about:
- Whether to filter at the response object level or deserialised JSON level
- How to handle partial matches (e.g. a field that is 90% clean)
- Whether failed filter checks should raise, return a sanitised object, or return None
Use spec-driven development. Before writing any code, produce:
1. An epic with acceptance criteria
2. Features broken down from the epic
3. User stories with acceptance criteria for each feature
4. A core contract with the minimal interface
5. Likely failure modes and assumptions to validate early
6. A strict traceable todo list
7. Unit test scenarios derived from the stories
The full spec, after a few iterations, that came out of this is on GitHub.
Notice what this gives Autopilot: a contract it cannot misinterpret, a todo list where each item maps to a story, and failure modes already named so they become test cases rather than surprises.
The model flagged two things I had not considered: that async exceptions in a plain httpx middleware chain can be silently swallowed if not structured carefully, and that config reloading mid-session needs a concurrency strategy.
Both would have been hard-to-diagnose bugs two hours into Autopilot.
Interactive
copilot --mode interactive suggests a command and waits for you to press Enter before running it. It is the read-and-confirm loop, which makes it well suited for the kind of targeted questions that come up while you are working through a spec.
For interactive mode, Auto is usually fine.
The questions you bring here are specific and bounded. Auto will route them to something fast and capable, which is exactly what you want. The one exception is when you are untangling genuinely complex behaviour: async concurrency semantics, something deep in the httpx request lifecycle, anything that requires the model to hold a lot of context and reason carefully. In those cases I switch to a stronger model manually, but I do not default to it.
For the content filtering agent, these were the kinds of questions I actually brought to interactive mode:
The spec says config must be reloadable without process restart. I am using a
module-level dict to cache compiled rules. Under concurrent async requests, is
there a window where one coroutine reads a partially updated cache? What is the
right primitive here given everything is running on the same event loop?
Story 3.1 says violations in nested lists should be reported with exact payload
paths. My traversal uses a recursive approach and the path for list items is
coming out as "responses[*].content" instead of "responses[0].content". Here is
the relevant code and the failing assertion:
[pasted code and assertion]
The PolicyFilter protocol has evaluate() as async. But the PII check I am
wiring in is a synchronous regex pass. If I wrap it with asyncio.to_thread(),
does that change the concurrency characteristics for the middleware hook, or is
it fine to just call it directly as a coroutine that happens to be non-blocking?
Each question has a specific failing thing, real context, and a specific decision to make. That is what interactive mode is for. The more I paraphrased or sanitised the context to make it feel like a clean example, the worse the answers got. Paste the actual stack trace, the actual failing assertion, the real config fragment.
The other thing that helped: stop using interactive mode for questions that should have been resolved in Plan.
“How should I structure the evaluation engine?” belongs in the spec. “Why is this traversal returning the wrong path for list items?” is an interactive question.
Autopilot
copilot --mode autopilot is the CLI equivalent of agent mode.
It executes shell commands autonomously to achieve a goal and will keep going until it is done or stuck. Fast when the plan is solid. Expensive when it is not.
For model selection here, Auto is doing something useful: it dynamically switches between lighter and heavier models depending on the step it is on. Simple file writes or dependency installs will get a cheaper model. A step that requires generating a critical implementation or calling a complex tool will escalate to a heavier one.
You do not need to pin a heavy model globally for an entire autopilot session. What matters more than model selection at this stage is prompt scope.
Point Autopilot at individual todo list items, not the whole epic.
“Implement story 3.1: nested traversal with path reporting, matching the PolicyFilter protocol in the spec” is a good Autopilot prompt. “Build the filtering agent” is not.
The spec gives Autopilot the contract, the acceptance criteria, and the boundaries. Without that, it makes design decisions silently and you find out when the tests fail.
Read what it produces before accepting it. Each todo item has acceptance criteria from the user stories, so you know exactly what done looks like before running the tests. Hand it one item, review against the criteria, run the relevant test scenarios, move to the next.
Wrapping Up
Plan, Interactive, and Autopilot are genuinely different jobs with genuinely different model needs.
Manually pin a strong reasoning model in Plan.
Trust Auto in Interactive for most things.
Let Auto’s dynamic routing do its job in Autopilot and focus on giving it one well-scoped todo item at a time.
That is where the iteration reduction actually comes from.
