
Orchestrating AI Inference at Scale
If serving AI inference were like running a restaurant, most teams start by having the waiter cook the food.
It works when there are three tables. It collapses when there are three hundred.
The same is true for AI systems. A single API server calling a model directly feels simple at first. But as usage grows, latency spikes, retries multiply, costs balloon, and reliability becomes unpredictable.
For tech leaders building serious AI platforms, the question is no longer “How do we call the model?” It becomes:
How do we orchestrate inference as a resilient, scalable system?
This article walks through the API + Worker architecture pattern for AI inference and post-processing — not as a coding trick, but as an operational strategy.
The Core Pattern
At scale, inference must be treated as a distributed system.
Logical Flow
Client → API → Durable Queue → Worker Pool → Model Service → Postprocessing → Result Store
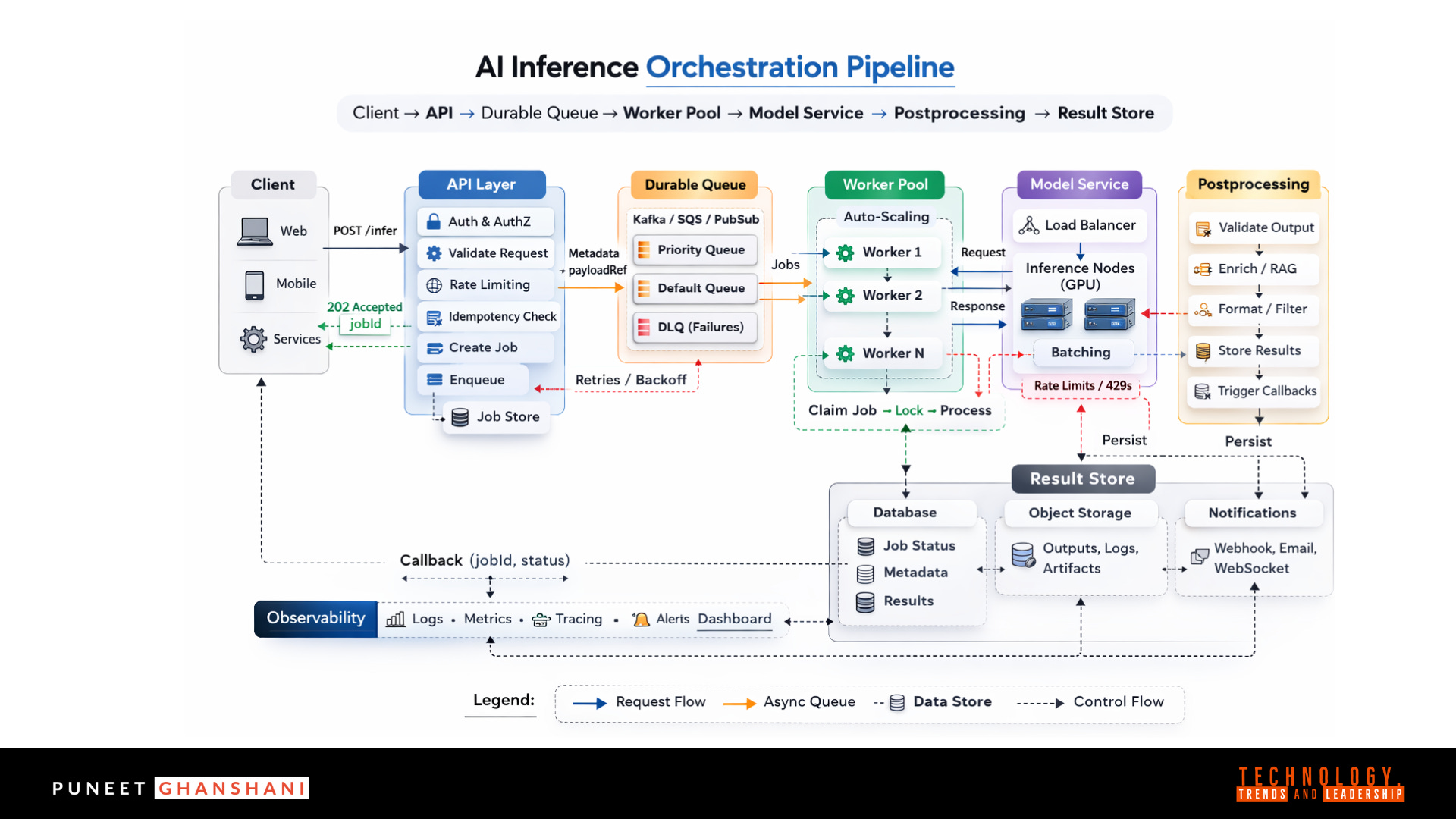
This is not architectural ceremony. It is separation of failure domains.
When traffic spikes, when a model slows down, or when retries surge, you want pressure isolated — not amplified.
This separation enforces discipline:
API: validate, authorize, enqueue
The API is your front door. It authenticates tenants, enforces rate limits, validates payloads, and turns requests into durable jobs. It does not execute inference.Queue: absorb burst traffic, guarantee durability
The queue is the shock absorber. It smooths bursty demand and guarantees work is not lost when services restart.Workers: execute inference and post-processing
Workers perform the heavy lifting — preprocessing, batching, calling models, handling retries, and persisting outputs.Store: persist results and job state
State must be explicit. Job lifecycle, artifacts, metadata, and outputs must survive crashes and restarts.
The API should not block on inference for unpredictable workloads. That responsibility belongs to workers.
Separate Ingress from Execution
Sync vs Async: A Strategic Decision
This is not an implementation detail. It is an architectural decision.
Synchronous (Blocking)
Use only when:
Inference latency is consistently < 1–2 seconds
UX requires immediate response
No batching opportunity exists
Risks:
Burst traffic amplifies tail latency
Retries compound instability
Scaling becomes tightly coupled to API capacity
Asynchronous (Default for Serious Workloads)
Async unlocks:
Horizontal worker scaling
Intelligent batching
Durable retries
Circuit-breaking
Back-pressure control
Sequence:
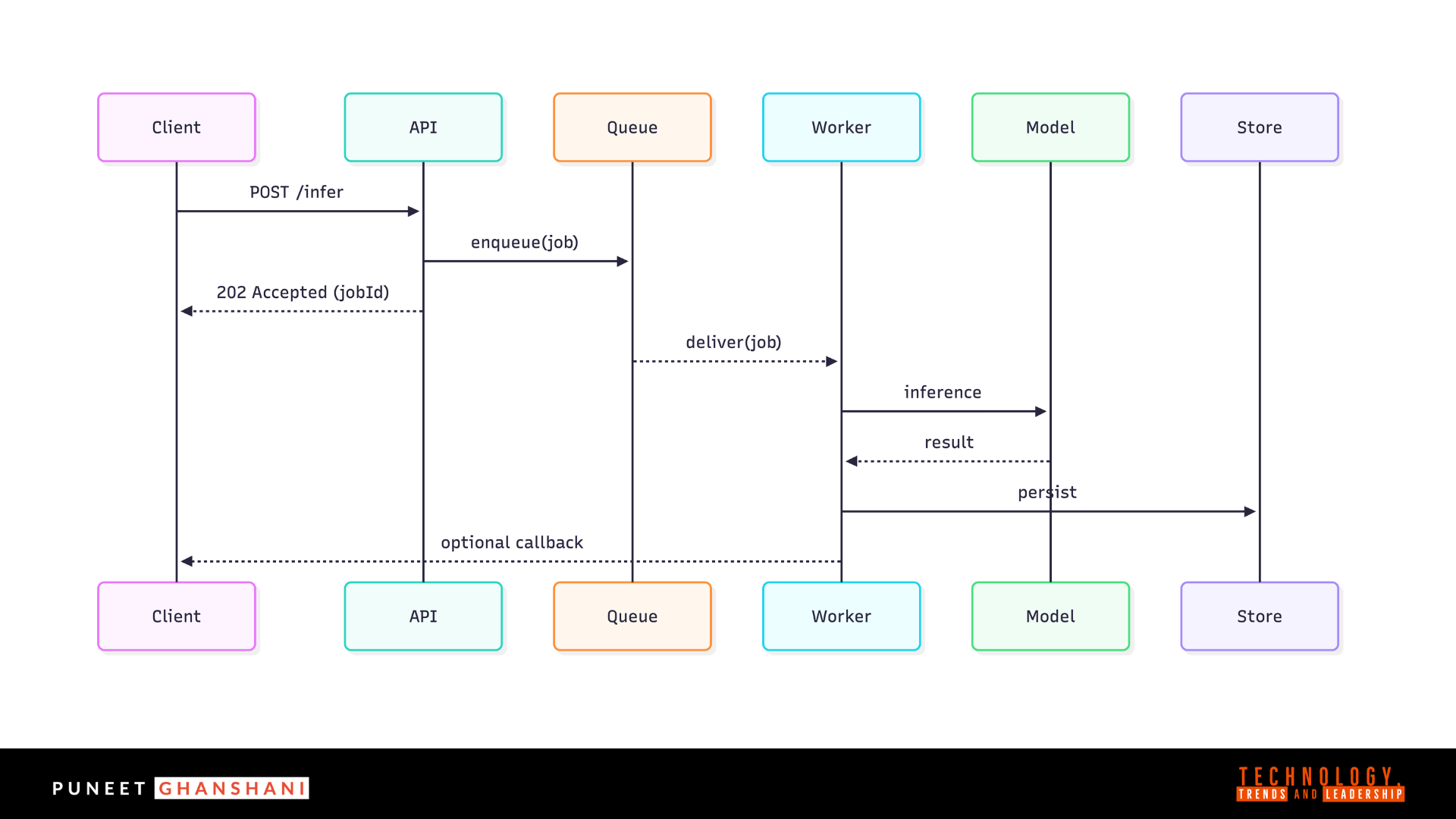
Async decouples user interaction from compute variability. That decoupling is what enables scale.
Your Control Plane Contract
Every inference request becomes a job and each job should have a schema (i.e. your control plane contract).
Principles:
Queue messages remain small
Large payloads are referenced via object storage
Job state is persisted separately
Idempotency is first-class
Example job schema:
{
"jobId": "uuid-1234",
"idempotencyKey": "user123:prompt:sha256",
"tenantId": "tenant-01",
"modelHint": "gpt-xx-small",
"payloadRef": "storage/inputs/uuid-1234.json",
"createdAt": "2026-02-22T12:00:00Z",
"priority": "interactive",
"attempts": 0,
"maxAttempts": 5,
"batchable": true,
"callbackUrl": "https://client.example/callback"
}
Track job states explicitly:
queuedrunningsucceededfailedcancelled
Expose via:
GET /v1/jobs/{jobId}
Once inference is modeled as a lifecycle-managed job, you gain operational control — visibility, retries, cancellation, auditing.
Request Routing
Request Routing should be lightweight and predictable through metadata.
Typical routing keys:
prioritytenantIdmodelHintlong_contextbatchable
Minimal router:
def route_request(payload):
if payload.priority == "interactive":
return "fast-model"
if payload.long_context:
return "large-context-model"
return "default-model"
The API decides where a request should go.
Workers decide how it is executed.
Complex orchestration logic belongs inside workers, not the API.
Worker Design: Stateless, Idempotent, Lease-Aware
Workers operate in a hostile environment.
They must assume:
Jobs can be delivered twice
Models can rate-limit
Pods can die mid-processing
Downstream calls can fail
Minimal processing flow:
def process_job(job):
if is_already_completed(job.jobId):
return "skipped"
lock = acquire_lock(job.jobId, ttl=60000)
if not lock:
return "locked"
try:
payload = download(job.payloadRef)
prepped = preprocess(payload)
if job.batchable:
batch = attempt_batching(job)
responses = send_batch_to_model(batch)
results = postprocess_batch(responses)
else:
response = call_model(prepped, model_hint=job.modelHint)
results = postprocess(response)
persist_result(job.jobId, results)
notify_client(job.callbackUrl, results)
mark_completed(job.jobId)
finally:
release_lock(lock)
Key properties:
Stateless workers → horizontal scaling
Locking + atomic state transitions → idempotency
Visibility timeout / lease extension → crash safety
Dead-letter queue → bounded retries
Workers are disposable. State is not.
Batching: Where Efficiency Is Won
GPU-backed inference is throughput-sensitive. Running single-item requests on GPU infrastructure is like sending one dish at a time to a commercial oven. Hence batching strategies are even more important:
Batching strategies:
Time-window batching
Size-based batching (tokens / payload size)
Hybrid threshold
Example loop:
def batching_loop(model_queue, max_batch_size, max_wait_ms):
buffer = []
start = now()
while True:
job = model_queue.pop(timeout=max_wait_ms)
if job:
buffer.append(job)
if len(buffer) >= max_batch_size or elapsed(start) >= max_wait_ms:
batch_request = merge_jobs(buffer)
responses = call_model(batch_request)
split_and_dispatch_responses(buffer, responses)
buffer = []
start = now()
Maintain request-to-response mapping carefully.
Without batching, GPU utilization and cost efficiency suffer.
Idempotency: Protecting Cost and Correctness
Retries are inevitable.
Submission logic:
def submit_inference(payload, idempotency_key=None):
key = idempotency_key or sha256(payload)
existing = idempotency_store.get(key)
if existing:
return existing.jobId, existing.status
job = create_job(payload, idempotencyKey=key)
idempotency_store.set(key, {"jobId": job.jobId, "status": "queued"})
enqueue(job)
return job.jobId, "queued"
Worker-level dedupe requires:
Atomic job transitions
Lock per
jobIdIdempotent persistence
Without this, duplicate GPU calls become silent cost leaks.
Retries, 429s, and Back-Pressure
Two failure domains:
API overload → return
429or503Model rate-limiting → respect
Retry-After
Retry logic:
def call_with_retries(call_fn, max_retries=5):
attempt = 0
while attempt <= max_retries:
try:
return call_fn()
except RateLimitError as e:
wait = parse_retry_after(e) or (2 ** attempt + jitter())
sleep(wait)
attempt += 1
except TransientError:
sleep(2 ** attempt + jitter())
attempt += 1
raise PermanentFailure()
Prefer queue-based delayed re-enqueueing over worker sleep loops.
Circuit Breaker Pattern
Prevent cascading GPU failure:
class CircuitBreaker:
def __init__(self, fail_threshold, reset_timeout):
self.fail_threshold = fail_threshold
self.reset_timeout = reset_timeout
self.fail_count = 0
self.opened_at = None
def allowed(self):
if self.opened_at and time.time() - self.opened_at < self.reset_timeout:
return False
return True
def record_failure(self):
self.fail_count += 1
if self.fail_count >= self.fail_threshold:
self.opened_at = time.time()
def record_success(self):
self.fail_count = 0
self.opened_at = None
When open:
Route to fallback model
Delay non-critical jobs
Shed load intentionally
Observability: The Leading Indicators
Correlate by jobId.
Track:
Enqueue → dequeue latency
Processing time
Model latency
Batch size
Retry count
429 frequency
Queue depth
DLQ growth
The two most predictive instability signals:
Sustained queue growth
Increasing time-in-queue
These indicate capacity mismatch before customer complaints surface.
Final Principles
Default to async for unpredictable workloads
Keep the API thin
Treat jobs as first-class control-plane objects
Make idempotency mandatory
Batch for cost efficiency
Respect 429s as system signals
Monitor queue depth continuously
The model determines capability.
The orchestration layer determines reliability, cost structure, and scale.
AI inference is not an API call.
It is a distributed system.
